
MLC Capping 101
If you haven’t read my first blog on sub-capacity MLC pricing, I recommend you read that first.
‘Soft capping’ is a common technique to control software costs based on the R4HA. IBM offers two ‘flavors’: Defined Capacity (DC) and Group Capacity (GC). The primary difference is that DC covers a single LPAR whereas GC works with multiple LPARs on the same CPC/CEC.
Note that ‘soft capping’ (DC/GC) is quite different from initial capping or absolute capping, the primary difference being that DC/GC is sensitive to the R4HA, whereas the other solutions limit instantaneous (“absolute”, as the name suggests) consumption. Soft capping is generally a more favorable solution when the primary goal is to control software costs based on the R4HA.
The first point to understand about soft capping is that the MLC invoice is based on the peak of the R4HA OR the peak of the DC/GC – whichever is LOWER. In each five-minute interval, there may be a DC/GC limit that is different from the R4HA peak. At the end of the hour, the average of the 12 DC/GC values is compared to the average of the 12 R4HA values and the LOWER VALUE is what SCRT will use for billing.
It may seem a simple strategy then to simply maintain lower DC/GC limits. The problem is that capping can impact application performance.
Application impact from Capping
If the R4HA exceeds the DC/GC limit, the LPAR(s) become ‘eligible’ for capping. WLM informs PR/SM to limit the provisioned capacity to the DC/GC limit. Should the application demand exceed this limit, it will be delayed.
Note that your WLM priority cannot guarantee protection from this. Your WLM Service Class (dispatching priority) can get you dispatched on to a logical processor within the LPAR but the logical processor must still be dispatched by PR/SM on to a physical processor in order to run. The LPAR (which is a logical construct) is simply not dispatched on the hardware as frequently as workload demands. Under such conditions, all applications in the LPAR may be impacted.
In short, DC/GC capping is at an LPAR SCOPE; to limit individual service classes, you may consider Resource Groups (although RG caps limit ‘instant’ rather than R4HA demand).
Automation and tracking application impact
Recall that I can lower my MLC by maintaining a DC average that is lower than the R4HA. Under such conditions, the LPAR is ‘considered’ for capping.
Whether or not applications are delayed depends on their current (not average) demand. If the current demand is lower than the R4HA, you can lower the DC to the demand level with no application impact. Should demand increase, you need to quickly raise the DC.
There are ISV solutions that automate this process. While none can predict the future, they are generally better than manual solutions.
In any capping environment, the key is to track when LPARs are ‘eligible’ for capping vs when applications are actually delayed by capping. Note the following chart from IntelliMagic Vision:
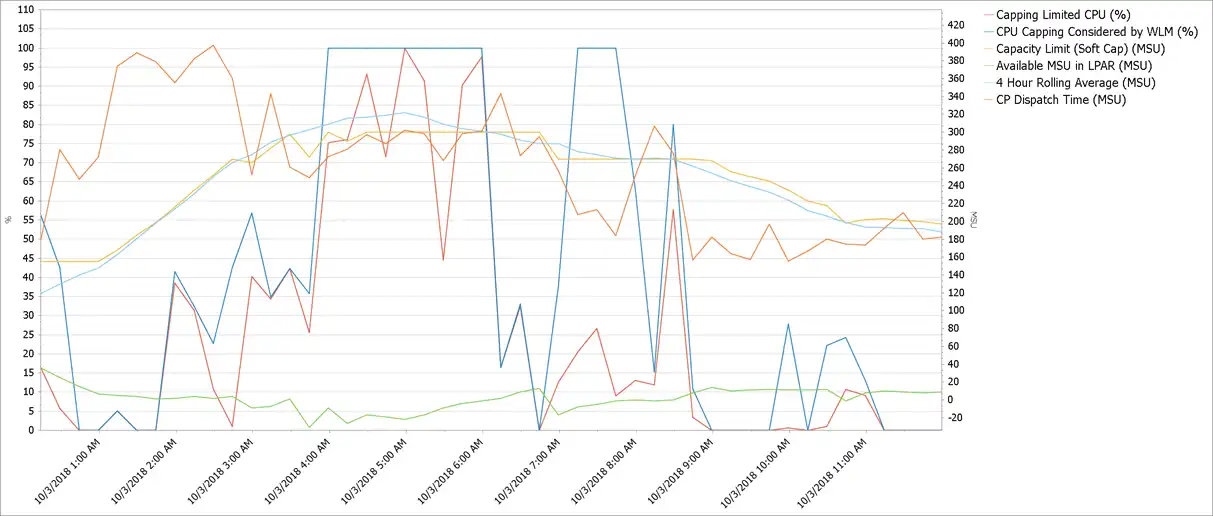
In this automated-capping environment, there are significant differences between “Capping Limited CPU” (applications are delayed) and “CPU Capping Considered” (no delay). Your solution should avoid the former while maximizing the latter.
Another solution worth considering is IBM’s Capacity Provisioning Manager. This software can track your key WLM Performance Indices and raise cap level(s) as a sort of ‘safety valve’.
Capping under Tailored Fit?
It has been suggested that capping could ‘fit’ here as well. I address this in the next blog, Throwing out the Rolling Four-Hour Average with Tailored Fit Pricing Enterprise Consumption.
How to get the most out of IBM’s zERT for tracking mainframe network traffic
IBM zERT provides very detailed statistics on the use of encryption protocols for all IP and TCP traffic to and from z/OS mainframes. Like with most SMF data sources, there is good data out of the box, but a significant analysis effort is required to get useful information.
This article's author
 John Baker
John Baker Share this blog
Related Resources
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Making Sense of the Many I/O Count Fields in SMF | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost addresses a question about the different fields in SMF records having different values.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today